
Name: Dhimant Adhikari | Pythonista
Role: Data Engineer
Education: Master's in CS
Location: Midland, Texas
Email: dhimantadhikari@gmail.com
Skills
PythonHi there! I'm Dhimant, a Computer Science graduate student at the University of Texas Permian Basin, deeply passionate about building data-driven tools and automating real-world workflows.
During my time as an Institutional Research Analyst, I built dashboards, automated reports with SQL and Power BI, and streamlined university processes using PowerApps and Power Automate. I love turning raw data into powerful insights and real impact.
My technical toolkit includes Python, Java, and JavaScript, along with tools like React, Node.js, SQL, and MongoDB. Whether it’s crafting a neural network visualizer, simulating phishing for cybersecurity awareness, or building wardrobe apps, I enjoy the challenge of solving problems creatively.
I’ve also had the honor of serving as a Chess Club President, Student Orientation Leader, and Graduate Senator—roles that shaped my leadership, communication, and teamwork skills.
Outside of code, you’ll catch me reading, reflecting, or plotting my next idea. Let’s connect—I’m excited about opportunities where I can build meaningful things, learn constantly, and grow with awesome people.
Education
Master of Science in Computer Science
Relevant Courses: Advanced (Web-Dev, OS, Database), Computer Architecture and Organization,
Genetic Algorithms, Convolutional Neural Networks, Real-Valued Neural Networks.
Cumulative GPA: 3.71
Highlights: Neural network projects, data visualization tools, Cache Memory Simulator.
Bachelor of Science in Computer Science
Relevant Courses: Object-Oriented Programming, Database Systems, and Software Development.
Cumulative GPA: 3.81
Highlights: Built a Java-based World Cup data analytics tool and contributed to campus tech workshops.
Work Experience
My App Store

Subset Sum Solver
This application solves the Subset Sum Problem with ease! It generates random subsets and uses genetic algorithm to find solution.
DownloadReal World Projects
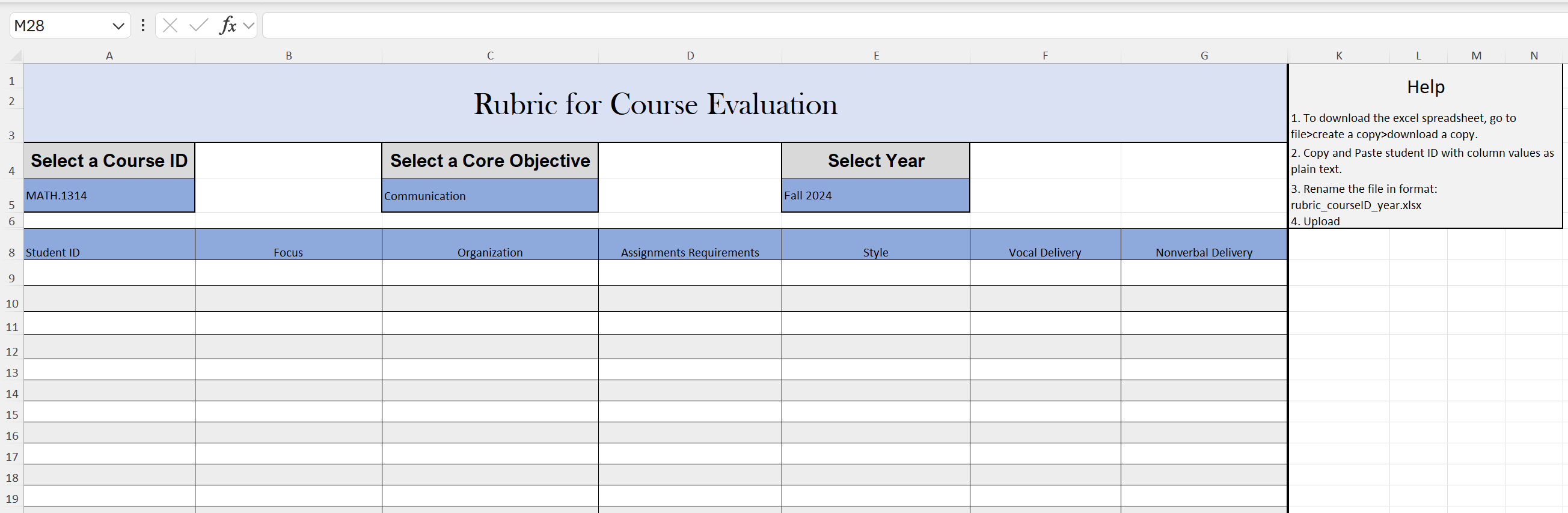
Here’s how it works: Professors visit the portal and scroll down to download the latest rubric. This Excel template is intelligently designed with dropdowns for course and core objective, and based on the selected objective, the corresponding evaluation columns auto-update. Professors then enter student data row by row, rename the file to a format like
rubric_math1314_2024.xlsx, and upload it through a PowerApps form.
Behind the scenes, Power Automate takes over—grabbing the uploaded file, storing it in the correct SharePoint folder, and prepping it for ingestion by Power BI. On the next scheduled refresh, the dashboard automatically categorizes each row of data into one of six core objective tables using Power Query logic. No matter the course or year, all submissions land in the correct place inside the Power BI model, fully parsed and ready for analysis.
The result? Admins no longer chase down files. Professors don’t need to email anyone. Dr. Collins doesn’t have to merge spreadsheets or manually clean up inconsistent data. And Dr. Edward? He simply opens the dashboard, refreshes the semantic model, and sees the updated reports—categorized, summarized, and beautifully visualized.
The hardest part? Designing the system from scratch. From structuring a flexible Excel template that adapts to any core objective, to building a dashboard that interprets uploads from an entire department, to writing a Power Automate flow that moves files invisibly—every step demanded custom thinking. Even PowerApps required a clever workaround to allow file attachments from a list, and then delete the placeholder record after saving the file to SharePoint.
What makes this system special isn’t just the automation—it’s the architecture. Every file follows a naming convention. Every submission flows through a predefined pipeline. And every update lands in a central, standardized data model. If all rubric files are uploaded correctly, the entire ecosystem runs on its own.
This is more than a tool—it’s an institution-grade solution built for clarity, scalability, and autonomy. And the best part? Once it's set up, there's nothing left to do but watch it run.
Dashboard Preview (PDF)
PowerApps Upload Portal

Dynamic Excel Rubric Template
The dashboard integrates data from Excel, SQL, and SharePoint to automate updates and maintain a centralized view of institutional reporting activity. Executives can monitor compliance, deadlines, and workflow progress without manual tracking or spreadsheet merging.
One of the most intuitive and powerful features of this dashboard is the monthly report interaction. Users can click on a specific month in the bar chart to highlight their area of interest. Once a month is selected, a "View Reports for This Month" button becomes active. Clicking this button performs two key actions:
- It dynamically changes the title of the Power BI page to say: “Reports for the month of [Selected Month]”, ensuring clarity of context.
- It navigates to a new page that displays a fully filtered, interactive table showing only the reports to be submitted for that selected month.
MasterList 2.0 isn’t just a dashboard—it’s a complete operational tool that supports planning, compliance tracking, and institutional effectiveness. It reduces human error, removes data redundancy, and presents insights in a way that empowers users at every level of the university.
Research Paper
Institution: University of Texas Permian Basin
EvolveAgent is an interactive educational tool designed to teach Genetic Algorithms (GA) to K-12 students through an engaging, game-based simulation. Built with Python and Pygame, it visualizes the evolution of agent populations using selection, crossover, and mutation mechanics. Students can experiment with adjustable parameters and see real-time evolution in action, making core AI concepts more accessible. The project was presented as a research paper and demonstration at UTPB, highlighting its contribution to AI education.
Academic Projects
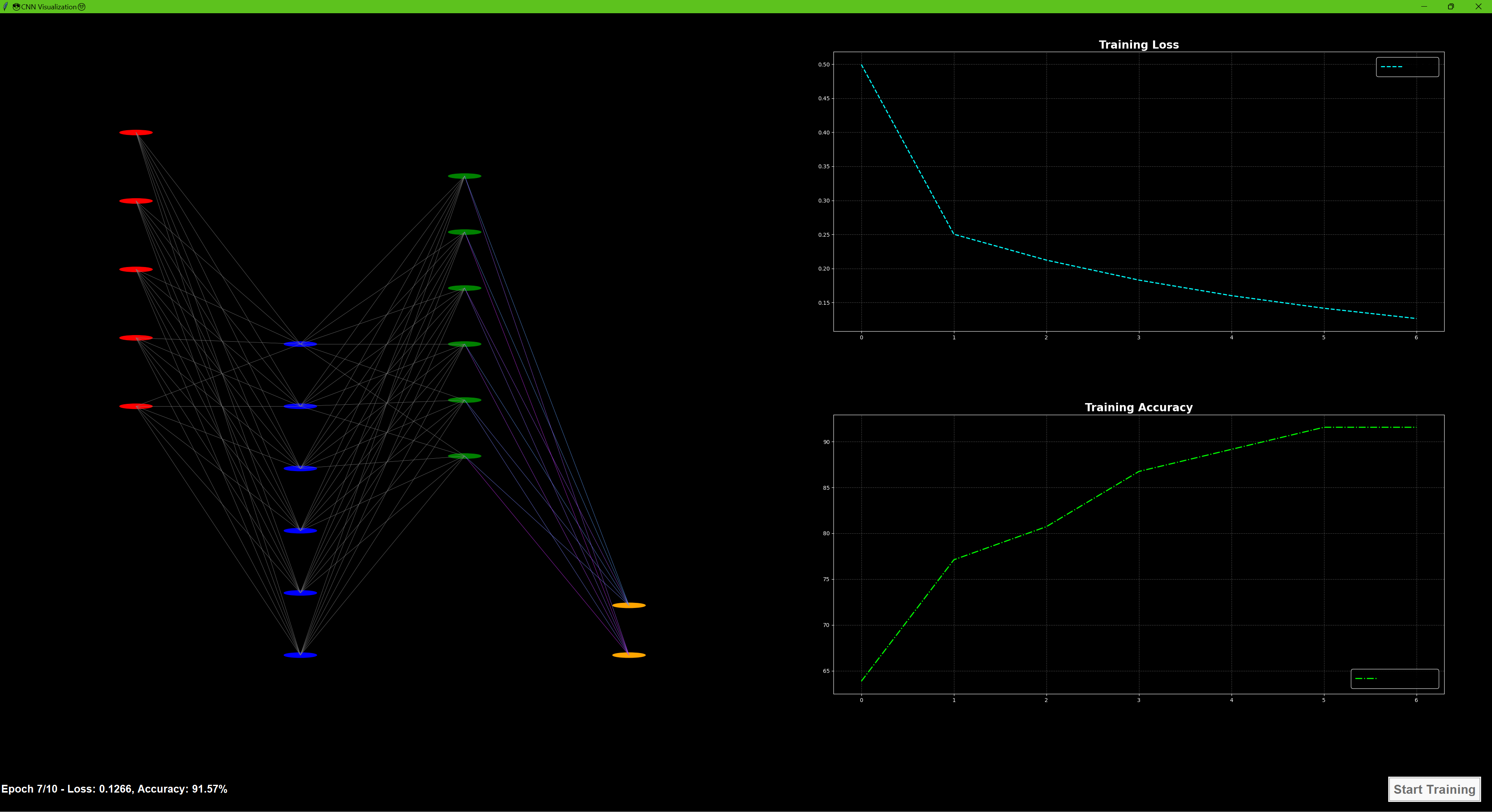
Convolutional Neural Network Visualization
- Displays the CNN structure: Input, Convolutional, Pooling, and Fully Connected layers.
- Shows real-time training metrics: Loss and Accuracy.
- Highlights dynamic weight updates through color-coded connections.
The core architecture includes a custom
GameWindow and GameLoop to manage rendering and ticks per second.
Each level is loaded from its own blueprint.
The physics system supports gravity, velocity, and collision detection, creating smooth and responsive gameplay.
This game showcases object-oriented architecture, modular design, and efficient rendering techniques using Java’s native libraries.
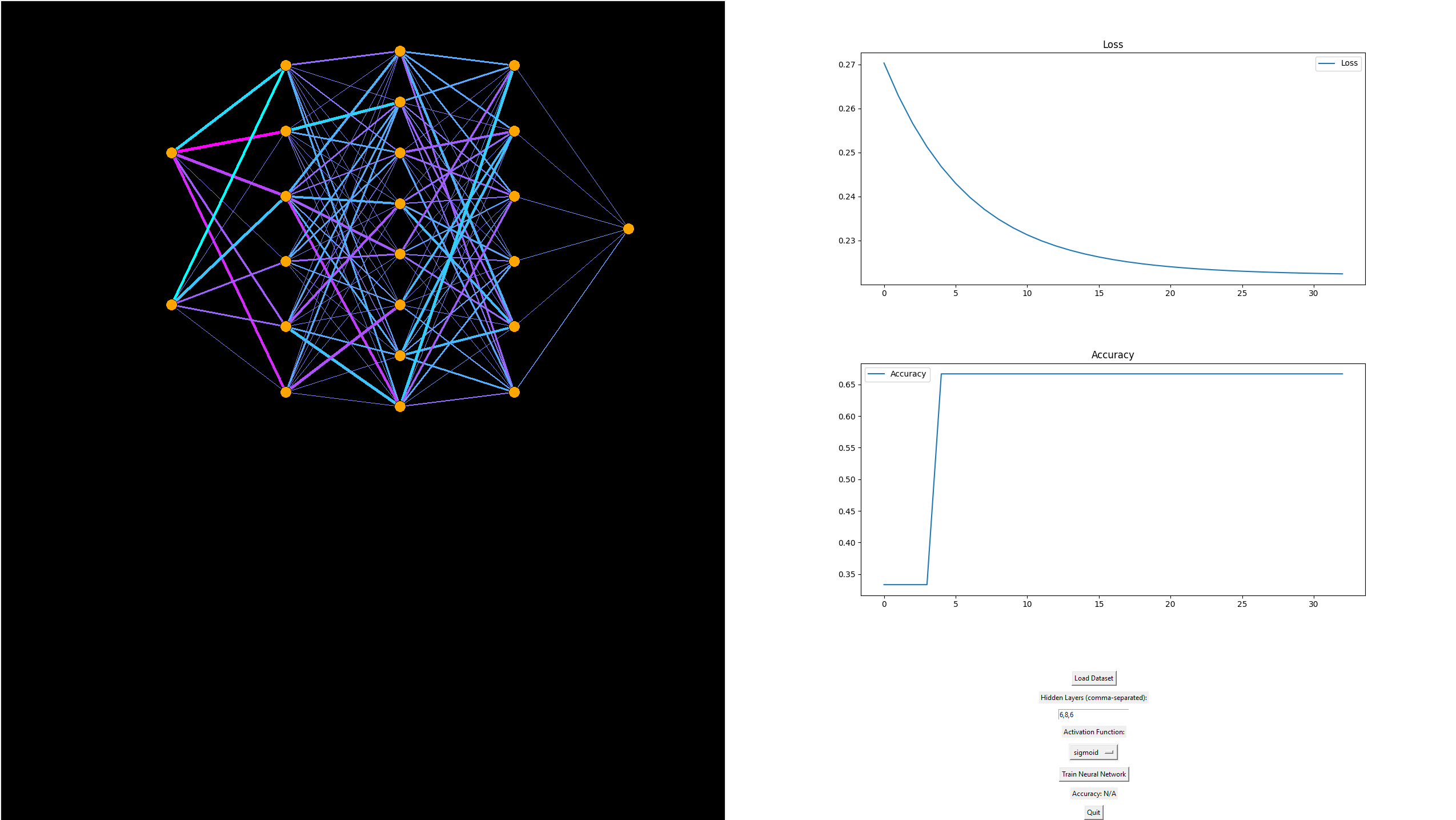
Key features include:
- Custom architecture configuration (input, hidden layers, output)
- Live updates of weights using animated, color-coded lines
- Neuron glow and activation-based color intensity
- Support for ReLU and Softmax functions with proper loss tracking
- Displays prediction values near output neurons after training
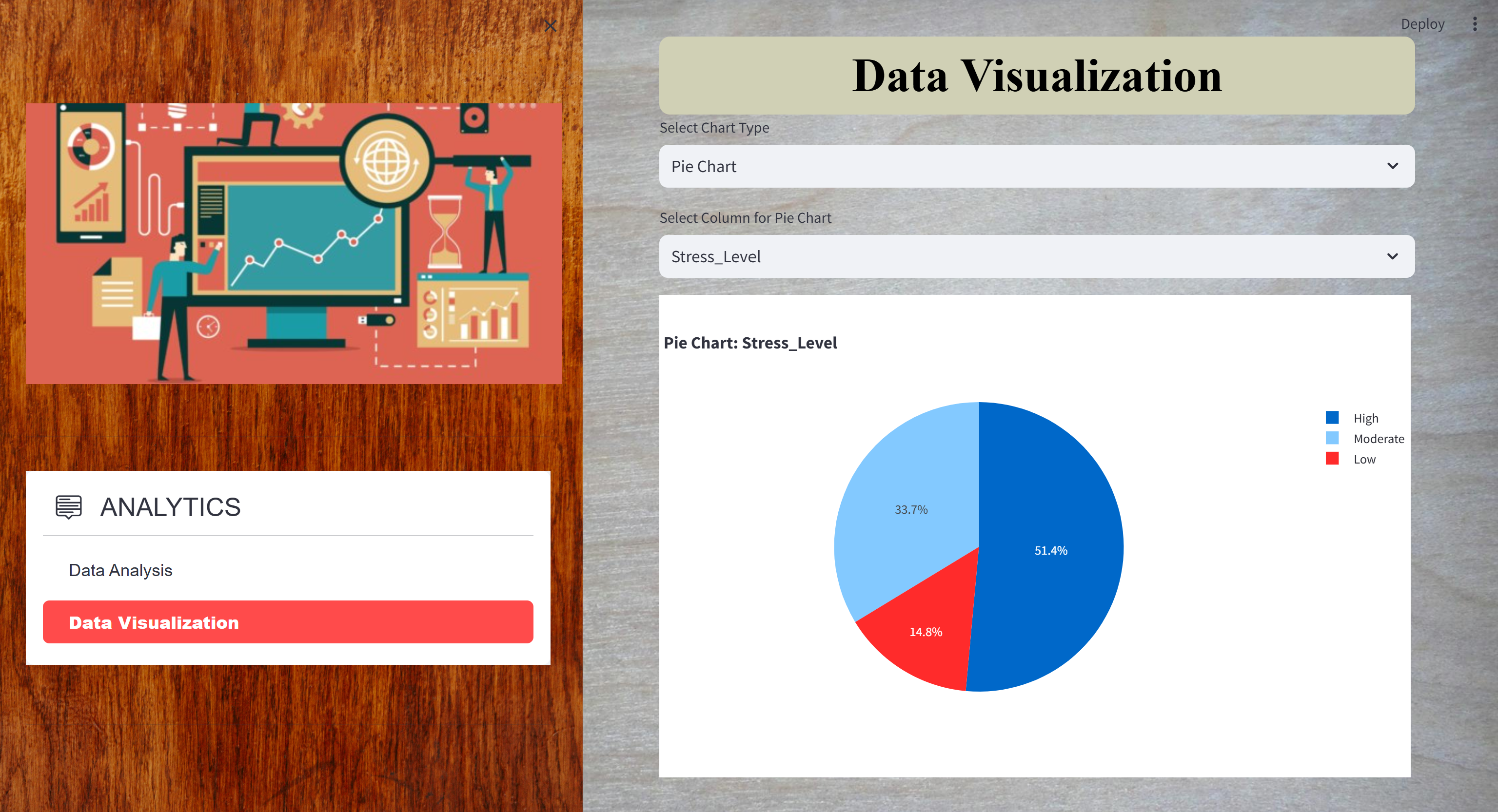
Comprehensive Data Analytics Project
NOTE: Please find the project demonstration video attached via YouTube.
This project demonstrates a phishing attack simulation designed to educate users on cybersecurity threats, specifically phishing scams. The website mimics the Facebook login and registration forms, complete with fields for personal information such as email and password. When users enter their credentials, they are stored in a Firebase Firestore database, simulating how real attackers might harvest sensitive data. The attack begins with a phishing email titled "Settlement Information," which lures victims by suggesting they may be eligible for compensation related to a Facebook lawsuit. The email creates a sense of urgency and directs recipients to the fake login page, where their credentials are captured. The project structure includes HTML for the form, JavaScript for database interaction, and Firebase for secure data storage. This simulation, detailed in a video demonstration, serves as a powerful tool for raising awareness about the dangers of phishing and the importance of cybersecurity practices.
NOTE: This project is private on GitHub. If you're interested in accessing the repository, please request access by contacting me directly or by submitting a pull request with a justification for why you need access.